





EMNLP2021 | 深兰DeepBlueAI团队少量数据关系抽取论文被录用
2021-11-09近日,EMNLP 2021在官网提前公布了今年的论文审稿结果,深兰DeepBlueAI团队论文《MapRE: An Effective Semantic Mapping Approach for Low-resource Relation Extraction》被录用。该论文提出了在低资源关系提取任务中融合同类别样本间句子相关性信息和关系标签语义两个方面的信息的方法,并在多个关系提取类任务的公开数据集的实验中得到了SOTA结果。
EMNLP(全称Conference on Empirical Methods in Natural Language Processing)是国际自然语言处理顶级会议,由ACL SIGDAT主办,每年举办一次,在Google Scholar计算语言学刊物指标中排名第二,主要关注统计机器学习方法在自然语言处理领域的应用。近几年随着大规模数据的机器学习方法的发展,该会议人数逐年增加,受到越来越广泛地关注。
EMNLP论文入选标准极为严格,EMNLP 2021共收到有效投稿3114篇,录用754篇,录用率仅为24.82%。按照惯例,EMNLP 2021评选了最佳长论文、最佳短论文、杰出论文和最佳Demo论文四大奖项,共7篇论文入选。
今年EMNLP 2021 将于11月7日 - 11日在多米尼加共和国蓬塔卡纳和线上联合举办,会议为期五天,复旦大学计算机科学学院教授黄萱菁将担任本次会议的程序主席。在即将召开的EMNLP学术会议上将展示自然语言处理领域的前沿研究成果,这些成果也将代表着相关领域和技术细分中的研究水平以及未来发展方向。
深兰DeepBlueAI团队的论文提出了在低资源关系提取任务中融合同类别样本间句子相关性信息和关系标签语义两个方面信息的方法,并在多个关系提取类任务的公开数据集的实验中得到了SOTA结果。
关系提取旨在发现给定句子中两个实体之间的正确关系,是NLP中的一项基本任务。该问题通常被视为有监督的分类问题,由大规模标记数据进行训练。近年来,关系提取模型得到了明显的发展。然而,训练样本过少时,模型性能会急剧下降。
在最近工作中,深兰DeepBlueAI团队利用小样本学习的进步来解决低资源问题。少样本学习的关键思想是学习一个用来比较query和support set samples中样本相似度的模型,这样,关系抽取的目标从学习一个通用的、准确的关系分类器变为学习一个将具有相同关系的实例映射到相近区域的映射模型。
在少样本学习的设定下,标签信息,即包含关系本身语义知识的关系标签,在训练和预测时并没有被模型用到。深兰DeepBlueAI团队的实验结果表明,在预训练和微调中结合上述标签信息和各关系类别的样本两类映射可以显着提高模型在少样本关系提取任务上的表现。
01
语义映射预训练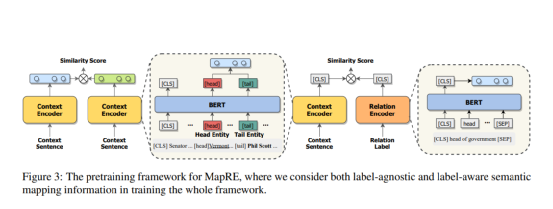
预训练部分的目标函数由三个部分组成:
CCR: 样本表示间损失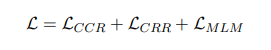
CRR:样本与标签间损失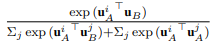
MLM:语言模型损失,同BERT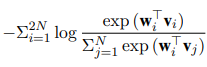
深兰DeepBlueAI团队采取类似CP (Peng et al., 2020)的方法中对模型进行预训练。不同之处在于团队还考虑了标签信息,使用Wikidata作为预训练语料库,去除了Wikidata和DeepBlueAI团队用于后续实验的数据集之间的重复部分。
本部分中,深兰DeepBlueAI团队使用BERT base作为基础模型,采用AdamW优化器,最大输入长度设置为60。深兰DeepBlueAI团队共训练了11,000步,其中前500步为warmup,batch size设为2040,学习比率为3e-5。
02
监督性关系抽取
本部分深兰DeepBlueAI团队一共试验了MapRE预训练模型的两种使用方式,即MapRE-L(直接使用全连接层对文本编码输出预测关系)和MapRE-R(采用关系编码器编码关系标签,再做相似度匹配),模型结构如图: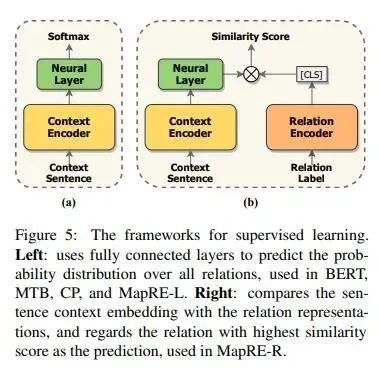
在监督性关系抽取任务中深兰科技评估两个基准数据集:ChemProt和Wiki80。前者包括56,000个实例和80种关系,后者包括10,065个实例和13种关系。
实验结果如下: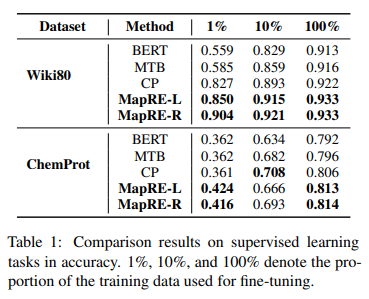
这里深兰DeepBlueAI团队重点关注低资源关系抽取,选取以下三个有代表性的模型进行比较。
1)BERT:该模型在文本的头实体和尾实体部分分别增加特殊的标记token,在BERT输出后接几个全连接层用于关系分类。
2)MTB (Soares et al., 2019):MTB模型假设无监督数据中头实体和尾实体相同的句子均为正样本对,即具有相同的关系。在测试阶段,对query和support set的相似度得分进行排名,将得分最高的关系作为预测结果。
3)CP (Peng et al., 2020):同MTB类似,我们的方法同CP模型的不同点在于,我们在预训练和微调时均考虑了标签信息。
我们可以观察到:
1)在BERT上进行预训练(即MTB, CP和MapRE)可以提高模型性能
2)比较MapRE-L与CP和MTB,在预训练期间添加标签信息可以显着提高模型性能,尤其是在资源极少的情况下,例如仅1%的训练集用于微调
3) 比较 MapRE-R 和 MapRE-L,其中前者在微调中也考虑了标签信息,表现出更好更稳定的实验结果
结果表明在预训练和微调中使用标签信息均可显著提高低资源监督性关系抽取任务上的模型性能。
03
少样本与零样本关系抽取
在少样本学习的情况下,模型需要在只有给定一定关系类别,每个类别少数样本的情况下进行预测。对于N way K shot问题,Support set S包含N个关系,每个关系有K个样本,查询集包含Q个样本,每个样本属于 N 个关系之一。
该模型结构如下: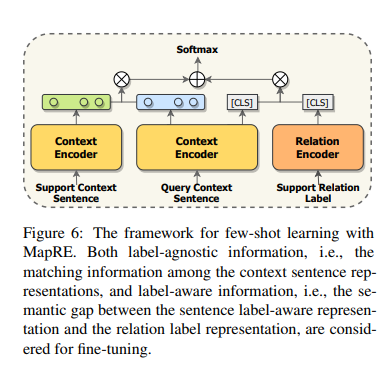
模型预测结果由下式得出: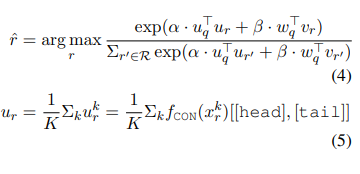
深兰DeepBlueAI团队在两个数据集上评估提出的方法:FewRel和NYT-25。FewRel 数据集包含70,000个句子和100个关系(每个关系有700个句子),数据来源为维基百科。其中64个关系用于训练,16个用于验证,以及20个用于测试。测试数据集包含 10,000 个句子,必须在线评估。NYT-25数据集是由Gao et al., 2019。DeepBlueAI团队随机抽取 10 个关系用于训练,5 个用于验证,10 个用于测试。
实验结果如下: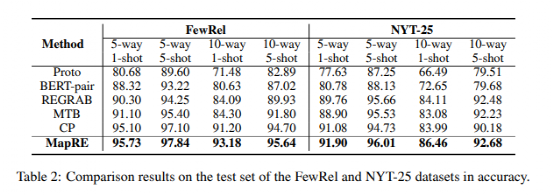
如上表所示,在所有的实验设置下,深兰DeepBlueAI团队提出的MapRE,由于在预训练和微调中均考虑了support set样本句子和关系标签信息,提供了稳定的性能表现,并大幅优于一系列baseline方法。结果证明了团队提出的框架的有效性,并表明了关系抽取中关系标签语义映射信息的重要性。
深兰DeepBlueAI团队进一步考虑了低资源关系抽取的极端条件,即零样本的情况。在该设定下,模型输入不包含任何support set样本。在零样本条件下,以上大部分少样本关系抽取框架不适用,因为其它该类模型的每个关系类别中至少需要有一个样本。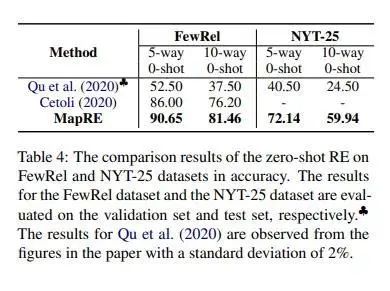
结果表明,与其它最近零样本学习工作相比,深兰DeepBlueAI团队提出的MapRE在所有设定下都获得了出色的表现,证明了MapRE的有效性。
总结
在这项工作中,深兰DeepBlueAI团队提出了一种同时考虑标签信息和样本信息的关系抽取模型,MapRE。大量实验结果表明,MapRE模型对监督性关系抽取、少样本关系抽取和零样本关系抽取任务中展示了出色的表现。结果表明样本和标签信息两者在预训练和微调中都起到了重要作用。在这项工作中,深兰DeepBlueAI团队没有研究领域迁移造成的潜在影响,我们将相关分析作为下一步的工作。
综上,深兰DeepBlueAI团队提出的MapRE模型结合了零样本和少样本学习的特点,结合了同关系样本和关系语义两个方面的信息,目前已在深兰科技智能数据标注平台文本关系抽取功能中得以应用,大幅提升了模型在少量训练样本下的表现,在数据的智能标注等领域可大幅节省人力,提升标注效率及标注质量。





